这套题,GPT-5.5、Opus 4.7加起来没考到「1分」,人类却拿了满分100?
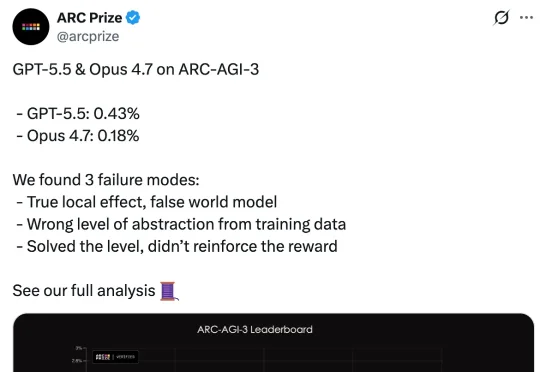
这套题,GPT-5.5、Opus 4.7加起来没考到「1分」,人类却拿了满分100?近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
来自主题: AI技术研报
9210 点击 2026-05-02 15:00
 搜索
搜索
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。

6位前DeepMind成员以元系统重塑大模型调用方式,该系统推出的Gemini 3 Pro优化技术在ARC-AGI-2上以54%的成绩夺得榜首,而成本仅为此前最优方法的一半。
AI社区掀起用大模型玩游戏之风!例如国外知名博主让DeepSeek和Chatgpt下国际象棋的视频在Youtube上就获得百万播放,ARC Prize组织最近也发布了一个贪吃蛇LLM评测基准SnakeBench。
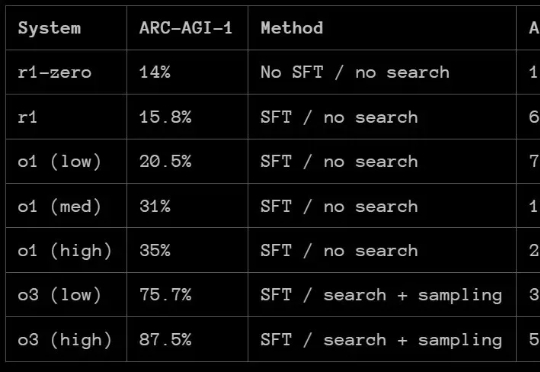
那么,DeepSeek-R1 的 ARC-AGI 成绩如何呢?根据 ARC Prize 发布的报告,R1 在 ARC-AGI-1 上的表现还赶不上 OpenAI 的 o1 系列模型,更别说 o3 系列了。但 DeepSeek-R1 也有自己的特有优势:成本低。